Perfect Timing and Latency
One of the strengths of the Web Audio API as compared to the <audio> tag is that it comes with a
low-latency precise-timing model.
Low latency is very important for games and other interactive applications since you often need fast auditory response to user actions. If the feedback is not immediate, the user will sense the delay, which will lead to frustration. In practice, due to imperfections of human hearing, there is leeway for a delay of up to 20 ms or so, but the number varies depending on many factors.
Precise timing enables you to schedule events at specific times in the future. This is very important for scripted scenes and musical applications.
Timing Model
One of the key things that the audio context provides is a
consistent timing model and frame of reference for time. Importantly, this
model is different from the one used for JavaScript timers such as
setTimeout, setInterval, and new
Date(). It is also different from the performance clock provided by
window.performance.now().
All of the absolute times that you will be dealing with in the Web
Audio API are in seconds (not milliseconds!), in the coordinate system of
the specified audio context. The current time can be retrieved from the
audio context via the currentTime property. Although the
units are seconds, time is stored as a floating-point value with high
precision.
Precise Playback and Resume
The start() function makes it easy to schedule precise
sound playback for games and other time-critical applications. To get this
working properly, ensure that your sound buffers are pre-loaded [see Loading and Playing Sounds]. Without a pre-loaded buffer, you will have to wait an
unknown amount of time for the browser to fetch the sound file, and then
for the Web Audio API to decode it. The failure mode in this case is you
want to play a sound at a precise instant, but the buffer is still loading
or decoding.
Sounds can be scheduled to play at a precise time by specifying the
first (when) parameter of the start() call. This
parameter is in the coordinate system of the AudioContext’s
currentTime. If the parameter is less than the currentTime, it is played immediately. Thus
start(0) always plays sound immediately, but to schedule
sound in 5 seconds, you would call start(context.currentTime +
5).
Sound buffers can also be played from a specific time offset by
specifying a second parameter to the start() call, and
limited to a specific duration with a third optional parameter. For
example, if we want to pause a sound and play it back from the paused
position, we can implement a pause by tracking the amount of time a sound
has been playing in the current session and also tracking the last offset
in order to resume later:
// Assume context is a web audio context, buffer is a pre-loaded audio buffer.varstartOffset=0;varstartTime=0;functionpause(){source.stop();// Measure how much time passed since the last pause.startOffset+=context.currentTime-startTime;}
Once a source node has finished playing back, it can’t play back
more. To play back the underlying buffer again, you need to create a new
source node (AudioBufferSourceNode) and call start():
functionplay(){startTime=context.currentTime;varsource=context.createBufferSource();// Connect graphsource.buffer=this.buffer;source.loop=true;source.connect(context.destination);// Start playback, but make sure we stay in bound of the buffer.source.start(0,startOffset%buffer.duration);}
Though recreating the source node may seem inefficient at first,
keep in mind that source nodes are heavily optimized for this pattern.
Remember that if you keep a handle to the AudioBuffer, you
don’t need to make another request to the asset to play the same sound
again. By having this AudioBuffer around, you have a clean
separation between buffer and player, and can easily play back multiple
versions of the same buffer overlapping in time. If you find yourself
needing to repeat this pattern, encapsulate playback with a simple helper
function like playSound(buffer) in an earlier code
snippet.
Scheduling Precise Rhythms
The Web Audio API lets developers precisely schedule playback in the future. To demonstrate this, let’s set up a simple rhythm track. Probably the simplest and most widely known drumkit pattern is shown in Figure 2-1, in which a hihat is played every eighth note, and the kick and snare are played on alternating quarter notes, in 4/4 time.

Assuming we have already loaded the kick, snare, and hihat buffers, the code to do this is simple:
for(varbar=0;bar<2;bar++){vartime=startTime+bar*8*eighthNoteTime;// Play the bass (kick) drum on beats 1, 5playSound(kick,time);playSound(kick,time+4*eighthNoteTime);// Play the snare drum on beats 3, 7playSound(snare,time+2*eighthNoteTime);playSound(snare,time+6*eighthNoteTime);// Play the hihat every eighth note.for(vari=0;i<8;++i){playSound(hihat,time+i*eighthNoteTime);}}
Once you’ve scheduled sound in the future, there is no way to unschedule that future playback event, so if you are dealing with an application that quickly changes, scheduling sounds too far into the future is not advisable. A good way of dealing with this problem is to create your own scheduler using JavaScript timers and an event queue. This approach is described in A Tale of Two Clocks.
{{jsbin width="100%" height="266px" src="http://orm-other.s3.amazonaws.com/webaudioapi/samples/rhythm/index.html"}}
Changing Audio Parameters
Many types of audio nodes have configurable parameters. For example,
the GainNode has a gain parameter that
controls the gain multiplier for all sounds going through the node.
Specifically, a gain of 1 does not affect the amplitude, 0.5 halves it,
and 2 doubles it [see Volume, Gain, and Loudness]. Let’s set up a graph as
follows:
// Create a gain node.vargainNode=context.createGain();// Connect the source to the gain node.source.connect(gainNode);// Connect the gain node to the destination.gainNode.connect(context.destination);
In the context of the API, audio parameters are represented as
AudioParam instances. The values of these nodes can be
changed directly by setting the value attribute of a param
instance:
// Reduce the volume.gainNode.gain.value=0.5;
The values can also be changed later, via precisely scheduled
parameter changes in the future. We could also use setTimeout to do this scheduling, but this is
not precise for several reasons:
Millisecond-based timing may not be enough precision.
The main JS thread may be busy with high-priority tasks like page layout, garbage collection, and callbacks from other APIs, which delays timers.
The JS timer is affected by tab state. For example, interval timers in backgrounded tabs fire more slowly than if the tab is in the foreground.
Instead of setting the value directly, we can call the
setValueAtTime() function, which takes a value and a start
time as arguments. For example, the following snippet sets the gain value
of a GainNode in one second:
gainNode.gain.setValueAtTime(0.5,context.currentTime+1);
Gradually Varying Audio Parameters
In many cases, rather than changing a parameter abruptly, you would
prefer a more gradual change. For example, when building a music player
application, we want to fade the current track out, and fade the new one
in, to avoid a jarring transition. While you can achieve this with
multiple calls to setValueAtTime as
described previously, this is inconvenient.
The Web Audio API provides a convenient set of
RampToValue methods to gradually change the value of any
parameter. These functions are linearRampToValueAtTime() and
exponentialRampToValueAtTime(). The difference between these
two lies in the way the transition happens. In some cases, an exponential
transition makes more sense, since we perceive many aspects of sound in an
exponential manner.
Let’s take an example of scheduling a crossfade in the future. Given a playlist, we can transition between tracks by scheduling a gain decrease on the currently playing track, and a gain increase on the next one, both slightly before the current track finishes playing:
functioncreateSource(buffer){varsource=context.createBufferSource();vargainNode=context.createGainNode();source.buffer=buffer;// Connect source to gain.source.connect(gainNode);// Connect gain to destination.gainNode.connect(context.destination);return{source:source,gainNode:gainNode};}functionplayHelper(buffers,iterations,fadeTime){varcurrTime=context.currentTime;for(vari=0;i<iterations;i++){// For each buffer, schedule its playback in the future.for(varj=0;j<buffers.length;j++){varbuffer=buffers[j];varduration=buffer.duration;varinfo=createSource(buffer);varsource=info.source;vargainNode=info.gainNode;// Fade it in.gainNode.gain.linearRampToValueAtTime(0,currTime);gainNode.gain.linearRampToValueAtTime(1,currTime+fadeTime);// Then fade it out.gainNode.gain.linearRampToValueAtTime(1,currTime+duration-fadeTime);gainNode.gain.linearRampToValueAtTime(0,currTime+duration);// Play the track now.source.noteOn(currTime);// Increment time for the next iteration.currTime+=duration-fadeTime;}}}
Custom Timing Curves
If neither a linear nor an exponential curve satisfies your needs,
you can also specify your own value curve via an array of values using the
setValueCurveAtTime function. With this function, you can
define a custom timing curve by providing an array of timing values. It’s
a shortcut for making a bunch of setValueAtTime calls, and
should be used in this case. For example, if we want to create a tremolo
effect, we can apply an oscillating curve to the gain
AudioParam of a GainNode, as in Figure 2-2.
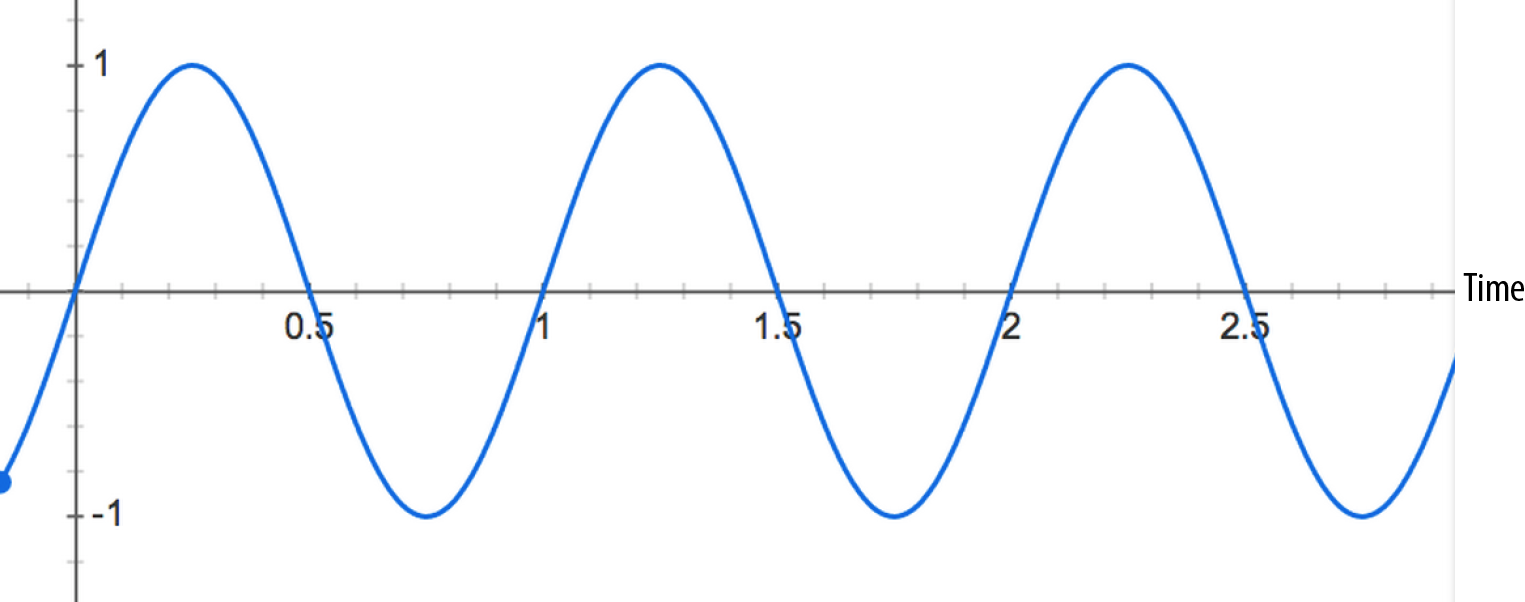
The oscillating curve in the previous figure could be implemented with the following code:
varDURATION=2;varFREQUENCY=1;varSCALE=0.4;// Split the time into valueCount discrete steps.varvalueCount=4096;// Create a sinusoidal value curve.varvalues=newFloat32Array(valueCount);for(vari=0;i<valueCount;i++){varpercent=(i/valueCount)*DURATION*FREQUENCY;values[i]=1+(Math.sin(percent*2*Math.PI)*SCALE);// Set the last value to one, to restore playbackRate to normal at the end.if(i==valueCount-1){values[i]=1;}}// Apply it to the gain node immediately, and make it last for 2 seconds.this.gainNode.gain.setValueCurveAtTime(values,context.currentTime,DURATION);
In the previous snippet, we’ve manually computed a sine curve and applied it to the gain parameter to create a tremolo sound effect. It took a bit of math, though.
This brings us to a very nifty feature of the Web Audio API that
lets us build effects like tremolo more easily. We can take any audio
stream that would ordinarily be connected into another
AudioNode, and instead connect it into any
AudioParam. This important idea is the basis for many sound
effects. The previous code is actually an example of such an effect called
a low frequency oscillator (LFO) applied to the gain, which is used to
build effects such as vibrato, phasing, and tremolo. By using the
oscillator node [see Oscillator-Based Direct Sound Synthesis], we can easily rebuild the
previous example as follows:
// Create oscillator.varosc=context.createOscillator();osc.frequency.value=FREQUENCY;vargain=context.createGain();gain.gain.value=SCALE;osc.connect(gain);gain.connect(this.gainNode.gain);// Start immediately, and stop in 2 seconds.osc.start(0);osc.stop(context.currentTime+DURATION);
The latter approach is more efficient than creating a custom value curve and saves us from having to compute sine functions manually by creating a loop to repeat the effect.